
来源:深科技财新网
华为AI芯片线路图发布
华为徐直军亮剑!昇腾芯片路线曝光:明年 Q1 推 950PR,2028 年 970 接棒,自研 HBM+2.5 倍带宽狂升!910C 已供货 BAT、追平 H100 八成性能,硬撼英伟达,硬扛美制裁!
一、开场:算力是中国 AI “命门”,华为要扛旗!
“算力过去是,未来也将继续是人工智能的关键,更是中国人工智能的关键!” 在华为全联接大会 2025 的舞台上,徐直军的声音掷地有声,像一把重锤砸在全球 AI 产业的神经上。
当美国制裁死死卡住台积电投片的脖子,当英伟达 Blackwell Ultra GB300 以 15PFLOPS(FP4)算力自居 “算力王者”,徐直军毫不避讳地撕开差距:“我们单颗芯片的算力相比英伟达是有差距”,但话锋一转,满是硬核底气,“华为有三十多年联人、联机器的积累,在联接技术上强力投资、实现突破,能做到万卡级超节点,从而一直做到世界上算力最强!” 这不是口号,是华为在算力围堵战中,亮出的破局利刃。
二、炸场!华为AI芯片路线图:三年四代,算力翻倍狂飙!
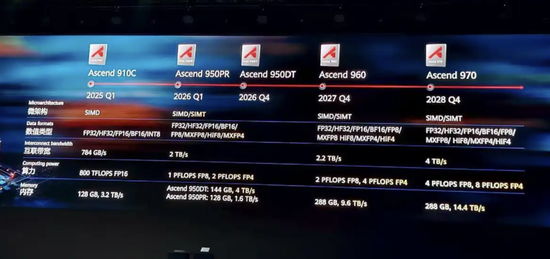
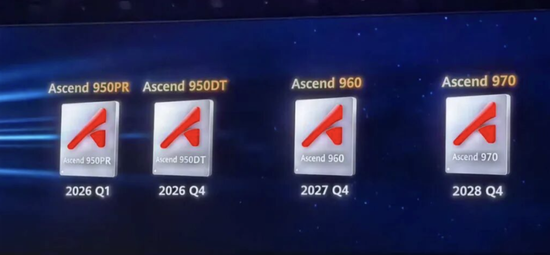
华为直接甩出昇腾芯片 “三年四代” 的炸裂规划财新网,每一步都踩在全球算力竞争的要害上:
1、2026 年 Q1,昇腾 950PR 横空出世!微架构从 SIMD 跃升至 SIMD/SIMT,算力直接干到 1PFLOPS(FP8)/2PFLOPS(FP4),还首次用上华为自研 HBM HiBL 1.0,互联带宽暴增至 2TB/s,数据格式支持更是拉满 FP32 到 HiF4,直接瞄准通用 AI 训练的 “硬骨头”;
2、2026 年 Q4,昇腾 950DT 接棒!升级 HBM HiZQ 2.0,针对数据中心高负载、高并发深度优化,把大规模数据处理的 “算力供给” 焊死在稳定线上;
3、2027 年 Q4,昇腾 960 再掀风暴!算力翻倍至 2PFLOPS(FP8)/4PFLOPS(FP4),HBM 内存容量飙到 288GB、带宽冲至 9.6TB/s,全新架构直接让复杂 AI 算法 “跑满速”;
4、2028 年 Q4,昇腾 970 登顶国产巅峰!算力再翻一倍达 4PFLOPS(FP8)/8PFLOPS(FP4),内存带宽炸到 14.4TB/s,直接代表国产 AI 芯片的最高水平,把高端 AI 应用的 “算力天花板” 捅破!
三、超节点杀招:灵衢协议架 “算力军团”,硬刚英伟达!
单颗芯片有差距?华为直接玩起 “集群碾压”!
徐直军亮出华为的 “杀手锏”—— 灵衢互联协议,这玩意儿能把无数昇腾芯片拼成 “算力军团”:以昇腾 950 为基础,能组超 50 万卡集群;以昇腾 960 为核心,直接干出超 99 万卡集群!

更狠的是,华为直接官宣全球最强超节点 Atlas 950 SuperPoD,8192 卡规模今年四季度就上市,比英伟达 2027 年才规划的 NVL576 系统还猛;2027 年 Q4,Atlas 960 SuperPoD 带着 15488 卡规模接棒,把 “算力最强” 的名号焊死在华为身上。

徐直军更是放话:“超节点将成为 AI 基础设施建设新常态!” 现在 CloudMatrix 384 超节点已部署 300 + 套、服务 20 + 客户,这就是华为的 “算力基建” 速度!
四、通算王炸 + 产业宣言:华为要做中国 AI 的 “坚实底座”
除了 AI 算力,徐直军还甩出全球首个通算超节点 TaiShan950 SuperPoD,基于鲲鹏 950 打造,最大 16 节点(32P)、48TB 内存,还支持内存 / SSD/DPU 池化,2026 年 Q1 就上市,直接喊出 “大型机、小型机终结者” 的豪言!
当美国试图用制裁锁死中国 AI 算力,华为用昇腾芯片的迭代、超节点的突破、通算能力的补位,硬生生闯出一条 “自主可控” 的算力大道 —— 这不是简单的产品发布,是中国 AI 在全球竞争中 “破局突围” 的宣战书!
 海量资讯、精准解读,尽在新浪财经APP
海量资讯、精准解读,尽在新浪财经APP
责任编辑:何俊熹 财新网
益通网提示:文章来自网络,不代表本站观点。
相关文章


沪深京指数
热点资讯
